Notification Center
Turn on/off sound
Show/Hide Coins Ticker
34 Gwei
| 🐌 Slow | 👌 Standard | ⚡️ Fast |
|---|---|---|
| 34 Gwei | 34 Gwei | 37 Gwei |
| ~120 secs | ~60 secs | ~15 secs |
| 🐌 Slow | 👌 Standard | ⚡️ Fast |
|---|---|---|
| 34 Gwei | 34 Gwei | 37 Gwei |
| ~120 secs | ~60 secs | ~15 secs |
Brother, our patience can be tested. It was and is tested. However, if we are determined, we can remain patient. And then, when our time does come, it will be like: "oh, already!" :)
I fully expect alt run this year. Relax now... because when the time comes, you will have plenty of excitement to look forward to.
I informed you of this top. Of bear phase, D Man's Macro fundamental report readers went into further details.. the point is, you my friend are once again at the right side of trade and expectation. There is currently not much to be made for regular spot traders, so patience is the right move.
Cheers my friend!
D Man
Mr. S just published a curious report about TIME.
Every chart consists of price and TIME. This one found an ancient method by stocks trader from seventies, adjusted by Mr. S for Bitcoin shows you when this bull cycle will reach bottom and when top according to this theory.
Very valuable report for strategising, I hope you find it useful. Unlock it here: https://blockchainwhispers.com/signals?signal_anchor=8364
I made this post (spot positions update) from Mr. M free for all now: https://blockchainwhispers.com/signals?signal_anchor=8359 Enjoy
Here's banana.
I know you're hungry. I know you want something different in life. Better. However, impatience is enemy of achievement.
How did it work for you before?
It's easy for me to write "1000x". But you know I'm ethics, trust and loyalty above and before anything. I try to write as conservative and as close to real as I can predict.
Maybe this banana will not satisfy your everpresent hunger, but 3x in slow times, might be better than 0x. Maybe that 3x will be foundation to next 10x becoming 30x. Maybe you'll skip it but will give you ideas of good ways to approach token-selection for your portfolio. Maybe it doesn't make even 3x... and only after I said all this I can say, but maybe, it also pleasantly surprises us!

While I'm waiting on the team, your BCW analysts are now checking projects with similar market category, similar development level where we have close confidence this will get and their marketcaps vs the expected marketcap at launch of this (implemented hard caps with the team in place)...
To understand, look, I don't want noobs, idiots etc. I know in most bullish days I'm not noob's favorite person as I'm telling them about caution education etc. However, I'm the only one followed in bear and bull markets, because I tell as transparently as educated as I am able.
My friend, the truth is at the end of the crypto bull run, there will not be all winners.
Yes, at some point many people might be in green, but due to their lack of proper perspective, they will fail. They will not book, chase the top, be stubborn at chart, having ego, having too much greed, whatever.
This particular opportunity, I know you'd like to see "gazillion X" — but really, of those screaming gazillion X on twitter, how many actually in this period achieved that gazillion X.
This find, at marketcap I assume, vs what the industry average on this developed project without much marketing, so basically taking every bit of figure conservatively, presents an easy and natural 3x opportunity vs the market.
If the market will fly, this will fly with it. Not as some AI coins, etc... but risk vs reward... is in our favor because we have one non-public advantage and that is we know the narrative change while most ignored that news. And plus now we have a slippage free entry.
So, let's say in this bull run avg of this category at this stage will be +10x, this one will be 3x first to category and 10x with the category it's 30x.
If the category or alts will not move, it is still 3x.
If it will drop the entire market 50% instead of pumping 10x, this thing is still +1.5x with some time delay as bear markets make.
Of course, no guarantees, but THIS is why I like such opportunity. Eventually, chart gaps are filled, liquidity voids cleared, and price-to-category equalized.
I know, I know, too advanced shit for avg noob. Wen Lambo? Wen moon?
For that, you have other channels. I'm very happy about this find, and I will invite you to check it when the time comes. I'll invite you not to put all your eggs in this basket, I'll structure it so that you must read and inform yourself before entering... so that at the end of the day, only the real holders get true BCW opportunity.
And even with this, yup, completely non-noob-friendly - we might still fail, project might end up being shit.
But we the real BCW know, given many such opportunities, edge by edge, where we are vs where the rest of the market is.
Remember all those dumps and pumps we predicted. Not all, but more than Twitter did, more than many if not most gurus did, many than sometimes even HUGE trading desks did (remember when I told you Microstrategy bought at the wrong timing, and it proved correct) - and they have a team of top pros...
Brother, we are united into something really powerful. Crypto awarded us with real people having almost the same opportunity as top pros. And we are staying sharp on top of it. This is why I didn't abandon crypto in bear times. Why I traded... so for this next bull run, I am more capable, more educated, more experienced to guide you with maximum edge.
Again, noobs I am sorry but, NO GUARANTEES!
Can you live with that?
Good, then join me and fellow BCW elite-hand brothers on the amazing crypto journey ahead!
D Man
Good news is yes, this year, I do expect to finally us, we all here in crypto to have a 2017-like alt run. Probably the last of its kind. This year, not this day or week. If you can live with it, you might get finally rewarded for years of being in crypto while others abandoned it after long and exhausting red periods. Cheers my loyal bro!
Imagine a guy developing something for years and the village already starts talking "he is nuts, never gonna deliver it" and one day he does, long after everyone stopped checking on him...
Similar find we have here. Not as strong though. They didn't invent anything breakthrough, but they reached that community-dulling moment because they were chasing something else for 2 years, now changed the direction and practically nobody noticed! They are very close to achieving it. And we, BCW, are among the very first to cash-in on the info.
Making a zero-slippage deal with the team, helped them restructure to buy out all previous investors since they got too small, and make even better, healthier (supertight) tokenomics that the market will appreciate.
Stay tuned, will tell more when I can/know.
My biggest concern, slippage at low marketcap is now solved (thanks to BCW reputation that makes teams listen). And tokenomics got even better (no airdrops, team got less, no coins for exchanges,... instead huge percentage for public and liquidity).
Will tell you more, this is just a small teaser why I'm happy about it. Not a gem of the year, but if it works out, it is easy and simple coin due to undervalue to market and category average due to info we know and others don't. It's not a privileged info, it's just something that most, professional market scanners, hobbyists etc overlooked because they assumed the team continued in the old direction, the news of the new direction didn't reach the community.
Sharing more in the following days.
Again, not a gem, but a really good, simple-to-understand opportunity imo.
Think of it this way: it's not a Lamborghini. It's a Prius, but a Prius offered at $1 starting auction and other people not knowing it's a real car, they think it's a toy. You know it's real. That's why I'm hot for this.
You might not reach valuation of Lambo, but if you reach even half the valuation of Prius and you paid $100, or $1000 for the $10,000 car, you did a great job, no?
Stay tuned.. (days, not hours, be relaxed)
Cheers!
I am very excited about this find. It is an undergem. It is not a gem only because it misses some technological breakthrough. Everything else: under the radar; price-to-opportunity; narrative... heck even chain is on the massive-gains train so to speak. I'll tell you about it soon. I made a nice progress with the team to do the crazy thing, to buy out the old investors so you have slippage--free entry. All this, thanks to BCW stellar reputation. Stay tuned. Likely early next week.
Cheers!
D Man
P.S. They asked me when. I said now. I want us actually to do this in red times. It will remain under the radar, and you'll be the lowest buyer possible. No one will be able to dump on you in profit. This is the strong position I like for BCW.
I might have something good to really good for you soon (days)... It is good for small wallets, a bit trouble for medium, a skip for whales this time due to liquidity.
It's a narrative change caught by so few. I love the opportunity and I think you'll be excited we discovered this timely as well. Cheers!
Halved. Weekend volume. Don't trust it. Have a nice weekend instead. Cheers!
P.S. The report is free. I think halving event is crypto public service.
So far it is predictable as we are heading into halving the price shows some green. It's a hook more than likely. S&P500 is continuing in its correction, and this gap is basically retail money expecting immediate post-halving results. Check the report, and then you'll know whether to expect immediate 100x long or not. Cheers my friend!
Halving is here. Miners rewards cut in half. You have the report here https://t.me/blockchainwhispersbaby/11349 about what to expect in price if history is to be asked. Cheers my friend!
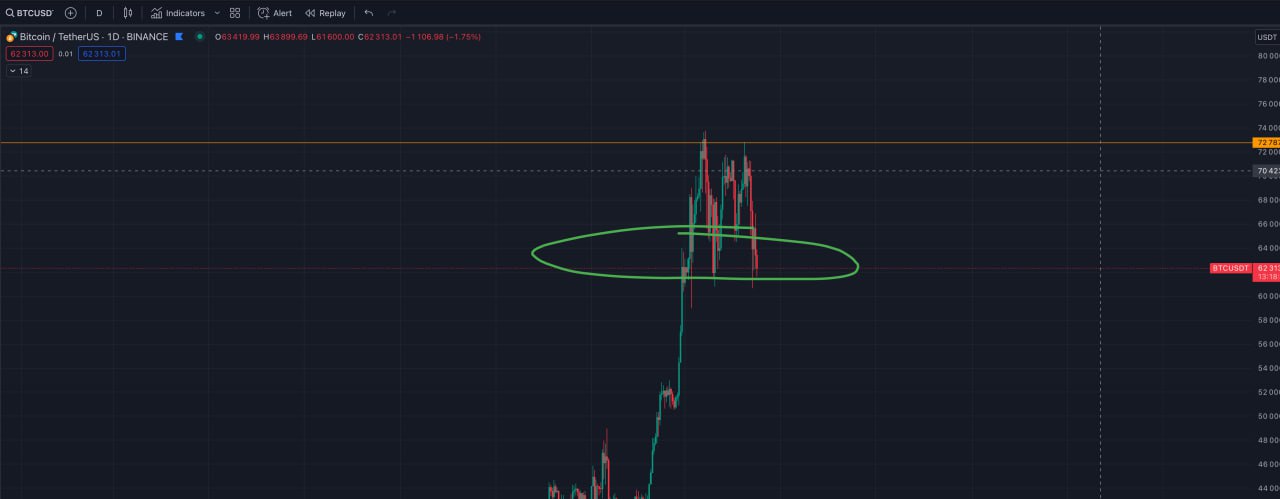
Remember this green drawing? Above = bullish, below = dump. We are retesting it now in a quite bad way. Just fyi.
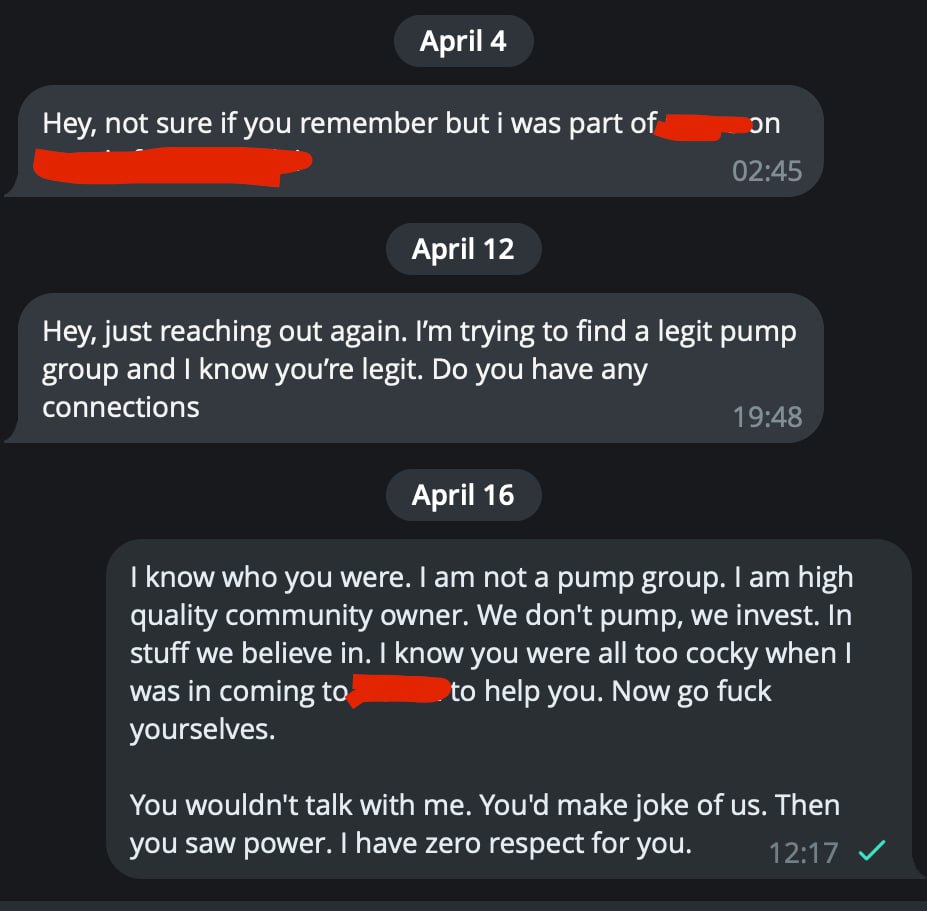
To all project founders who ignore good-intent people, are cocky to them, but once they see the power (like BCW) they get on their knees to suck a dick. FUCK YOU!
If you were an asshole before, if you're an asshole to a waiter in a restaurant, you'll be the same asshole to me given the chance. I want nothing to do with you. You don't deserve BCW.
Many guys like this guy. I remember him, founder of a project, a fork that was good idea. I came anon to give them top notch advice, they were ubercocky. Later, when they saw BCW power, they started to suck dick.
You know that joke: "Jenny would you suck a dick for a million bucks?"
- "for a million, yes"
- "what about for $10?"
She slaps him.
"who do you think I am"
- "we already established that, now we're just negotiating"
—-
The point is, if they are assholes, they are assholes. Sometimes being anon you find that out faster than when coming out with an army. Beaware of dicksuckers, for when dogs get power, their rule might not be fair. Cheers!
On a macro scale, if you zoom out just a bit from second-to-second thinking... if you relax... crypto this year I expect to be very rewarding. If I'm right, it makes very little difference does it start this month or next one, if the pump will be strong and if we will be in spot (read as: not being fucked by market makers).
Spot hold what you truly like.
Enjoy crypto.
Or micro trade it, time the market. I share with you the edge I find (and it's quite both powerful and often). According to your preference. Cheers!
Discussions
top 3 breaking news
Using data from CryptoQuant, Bloomberg has revealed that the Bitcoin funding rate—the cost for traders to open long positions in Bitcoin's perpetual ...
a
a
a
a
a
a
Bloomberg the Company & Its ProductsThe Company & its ProductsBloomberg ... Which they also did with, you know, VR and all the kind of previous crypto ...
a
a
a
a
a
a
The Securities and Exchange Commission is evaluating whether exchanges’ current surveillance and enforcement mechanisms can handle Bitcoin exchange-traded products (ETPs).
a
a
a
a
a
a
The collaboration is the first phase of Subsquid's much anticipated Solana blockchain expansion. Subsquid is a cutting-edge query engine and ...
a
a
a
a
a
a
At the heart of every blockchain network lies a critical component that ensures the integrity, security, and decentralization of the underlying ...
a
a
a
a
a
a
How much revenue do blockchains generate? How do Layer-1 blockchains reward validators? Is the crypto economy sustainable in the long term?
a
a
a
a
a
a
In a first-of-its-kind transaction, the city of Quincy, Massachusetts, issued $10 million of tax-exempt bonds using blockchain technology, ...
a
a
a
a
a
a
Blockchain protocol agnostic solution provides interoperability across chains. Member of the European Central Bank market group for Euro CBDCs. Seeing ...
a
a
a
a
a
a
DePIN project Natix raises funds ahead of token launch and airdrop on Solana The Block
a
a
a
a
a
a
April 25, 2024 (Investorideas.com Newswire) Meta Platforms Inc., formerly known as Facebook, continues its dominance in social platforms under the leadership of its CEO, Mark Zuckerberg.
a
a
a
a
a
a
Memecoins are popular among crypto's degen crowd, but among builders, they appear as something that undermines the industry's fundamentals. The post Memecoins are ‘undermining’ the long-term vision of crypto, a16z CTO says appeared first on Crypto Briefing.
a
a
a
a
a
a
Bloomberg ETF analyst Eric Balchunas says crypto investors should reign in their expectations over a spate of recently approved spot Bitcoin and ...
a
a
a
a
a
a
According to Bloomberg, Bitcoin traders seem to have reduced their bets on the world's largest cryptocurrency as its two major driving forces ...
a
a
a
a
a
a
CARV announces a $10M Series A funding to enhance its gaming and AI data layer, supported by Tribe Capital and IOSG Ventures. The post Gaming and AI structure CARV secures $10 million in series A funding appeared first on Crypto Briefing.
a
a
a
a
a
a
Event notifications in MinIO may not seem thrilling at first, but once you harness their power, they illuminate the dynamics within your storage buckets.
a
a
a
a
a
a
:::info This paper is available on arxiv under CC 4.0 license. Authors: (1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (2) Chunyang Chen, Monash University, Melbourne, Australia; (3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author; (4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author. ::: Table of Links Abstract and Introduction Motivational Study and Background Approach Experiment Design Results and Analysis Discussion and Threats to Validity Related Work Conclusion and References 4 EXPERIMENT DESIGN 4.1 Research Questions • RQ1: (Bugs Detection Performance) How effective of InputBlaster in detecting bugs related to text input widgets? \ For RQ1, we first present some general views of InputBlaster for bug detection, and then compare it with commonly-used and state-of-the-art baseline approaches. \ • RQ2: (Ablation Study) What is the contribution of the (sub-) modules of InputBlaster for bug detection performance? \ For RQ2, We conduct ablation experiments to evaluate the impact of each (sub-) module on the performance. \ • RQ3: (Usefulness Evaluation) How does our proposed InputBlaster work in real-world situations? \ For RQ3, we integrate InputBlaster with the GUI testing tool to make it automatically explore the app and detect unseen inputrelated bugs, and issue the detected bugs to the development team. 4.2 Experimental Setup For RQ1 and RQ2, we crawl 200 most popular open-source apps from F-Droid [3], and only keep the latest ones with at least one update after September 2022 (this ensures the utilized apps are not overlapped with the ones in Sec 3.3). Then we collect all their issue reports on GitHub, and use keywords (e.g., EditText) to filter those related to text input. Finally, we obtain 126 issue reports related to 54 apps. Then we manually review each issue report and the mobile app, and filter it according to the following criteria: (1) the app wouldn’t constantly crash on the emulator; (2) it can run all baselines; (3) UIAutomator [65] can obtain the view hierarchy file for context extraction; (4) the bug is related to text input widgets; (5) the bug can be manually reproduced for validation; (6) the app is not used in the motivational study or example dataset construction. Please note that we follow the name of the app to ensure that there is no overlap between the datasets. Finally, 31 apps with 36 buggy text inputs remain for further experiments. \ We measure the bug detection rate, i.e., the ratio of successfully triggered crashes in terms of all the experimental crashes (i.e., buggy inputs), which is a widely used metric for evaluating GUI testing [8, 27, 43]. Specifically, with the generated unusual input, we design an automated test script to input it into the text input widgets, and automatically run the “submit” operation to check whether a crash occurs. If no, use the script to go back to GUI page with the input widget if necessary, and try the next generated unusual input. As long as a crash is triggered for a text input widget, we treat it as successful bug detection and will stop the generation for this widget. Note that our generated unusual input is not necessarily the same as the one provided in the issue report, e.g., -18 vs. -20, as long as a crash is triggered after entering the unusual inputs, we treat it as a successful crash detection. \ For a fair comparison with other approaches, we employ two experimental settings, i.e., 30 attempts (30 unusual inputs) and 30 minutes. We record the bug detection rate under each setting (denoted as “Bug (%)” in Table 2 to Table 5), and also record the actual number of attempts (denoted as “Attempt (#)”) and the actual running time (denoted as “Min (#)”) when the crash occurs to fully understanding the performance. \ For RQ3, we further evaluate the usefulness of InputBlaster in detecting unseen crash bugs related to text input. A total of 131 apps have been retained. We run Ape [26] (a commonly-use automated GUI testing tool) integrated with InputBlaster, for exploring the mobile apps and getting the view hierarchy file of each GUI page. \ We use the same configurations as the previous experiments. Once a crash related to text input is spotted, we create an issue report by describing the bug, and report them to the app development team through the issue reporting system or email. 4.3 Baselines Since there are hardly any existing approaches for the unusual input generation of mobile apps, we employ 18 baselines from various aspects to provide a thorough comparison. \ First, we directly utilize ChatGPT [58] as the baseline. We provide the context information of the text input widgets (as described in Table 1 P1), and ask it to generate inputs that can make app crash. \ Fuzzing testing and mutation testing can be promising techniques for generating invalid inputs, and we apply several related baselines. Feldt et al. [24] proposed a testing framework called GoldTest, which generates diverse test inputs for mobile apps by designing regular expressions and generation strategies. In 2017, they further proposed an invalid input generation method [55] based on probability distribution (PD) parameters and regular expressions, and we name this baseline as PDinvalid. Furthermore, we reuse the idea of traditional random-based fuzzing [13, 41], and develop a RandomFuzz for generating inputs for text widgets. In addition, based on the 50 buggy text inputs from the GitHub dataset in Section 3.3.1, we manually design 50 corresponding mutation rules to generate the invalid input, and name this baseline as ruleMutator. \ Furthermore, we include the string analysis methods as the baselines, i.e., OSTRICH [15] and Sloth [14]. They aim at generating the strings that violate the constraints (e.g., string length, concatenation, etc), which is similar to our task. OSTRICH’s key idea [15] is to generate the test strings based on heuristic rules. Sloth [14] proposes to exploit succinct alternating finite-state automata as concise symbolic representations of string constraints. \ There are constraint-based methods, i.e., Mobolic [8] and TextExerciser [27], which can generate diversified inputs for testing the app. For example, TextExerciser utilizes the dynamic hints to guide it in producing the inputs. \ We also employ two methods (RNNInput [43] and QTypist [44]) which aim at generating valid inputs for passing the GUI page. In addition, we use the automated GUI testing tools, i.e., Stoat [61], Droidbot [39], Ape [26], Fastbot [12], ComboDroid [67], TimeMachine [23], Humanoid [40], Q-testing [53], which can produce inputs randomly or following rules to make app running automatically. \ We design the script for each baseline to ensure that it can reach the GUI page with the text input widget, and run them in the same experimental environment (Android x64) to mitigate potential bias.
a
a
a
a
a
a
The contemporary discourse on generative Artificial Intelligence (AI) presents a nuanced and dualistic narrative of technological development.
a
a
a
a
a
a
Layer-1 blockchains have three sources of funding for the validators supporting their networks: unlocked tokens from the total supply, minting of new tokens and network fees paid by the users. We explore major Layer-1 blockchains to find out how sustainable are their models without token subsidies, pros and cons of different approaches to crypto economy.
a
a
a
a
a
a
I was really stressed out when I had to manage multiple jobs for the first time. However, these strategies/tools helped me overcome it successfully
a
a
a
a
a
a
:::info This paper is available on arxiv under CC 4.0 license. Authors: (1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (2) Chunyang Chen, Monash University, Melbourne, Australia; (3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author; (4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author. ::: Table of Links Abstract and Introduction Motivational Study and Background Approach Experiment Design Results and Analysis Discussion and Threats to Validity Related Work Conclusion and References 3 APPROACH This paper aims at automatically generating a batch of unusual text inputs which can possibly make the mobile apps crash. The common practice might directly produce the target inputs with LLM as existing studies in valid input generation [44] and fuzzing deep learning libraries [20, 21]. Yet, this would be quite inefficient for our task, because each interaction with the LLM requires a few seconds waiting for the response and consumes lots of energy. Instead, this paper proposes to produce the test generators (a code snippet) with LLM, each of which can generate a batch of unusual text inputs under the same mutation rule (e.g., insert special characters into a string), as demonstrated in Figure 4 ⑤. \ \ To achieve this, we propose InputBlaster which leverages LLM to produce the test generators together with the mutation rules which serve as the reasoning chains for boosting the performance, and each test generator then automatically generates a batch of unusual text inputs, as shown in Figure 3. In detail, given a GUI page with text input widgets and its corresponding view hierarchy file, we first leverage LLM to generate the valid text input which can pass the GUI page (Sec 3.1). We then leverage LLM to produce the test generator which can generate a batch of unusual text inputs, and simultaneously we also ask the LLM to output the mutation rule which serves as the reasoning chain for guiding the LLM in making the effective mutations from valid inputs (Sec 3.2). To further boost the performance, we utilize the in-context learning schema to provide useful examples when querying the LLM, from online issue reports and historical running records (Sec 3.3). 3.1 Prompt Generation for Valid Input InputBlaster first leverages LLM to generate the valid input which will serve as the target towards which the following mutation can be conducted. The context information relates to the input widgets and its belonged GUI page can provide important clues about what the valid input should be, therefore we input this information into LLM (in Section 3.1.1). In addition, we also include the dynamic feedback information when interacting with the input widgets (in Section 3.1.2), and the constraint categories we summarized in the previous section (in Section 3.1.3) to improve the performance. Furthermore, besides the valid text input, we also ask LLM to output its inferred constraints for generating the valid input which will facilitate the approach to generating the mutation rules in the next section. We summarize all the extracted information with examples in Table 1. \ 3.1.1 Context Extraction. The context information is extracted from the view hierarchy file, which is easily obtained by automated GUI testing tools [26, 48, 49, 61]. As shown in Table 1, we extract the text-related field of the input widget which indicates how the valid input should be. In detail, we extract the “hint text”, “resource id”, and ‘text’ fields of the input widget, and utilize the first non-empty one among the above three fields. \ We also extract the activity name of the GUI page and the mobile app name, and this global context further helps refine the understanding of the input widget. In addition, we extract the local context of the input widget (i.e., from nearby widgets) to provide thorough viewpoints and help clarify the meaning of the widget. The candidate information source includes the parent node widgets, the leaf node widget, widgets in the same horizontal axis, and fragment of the current GUI page. For each information source, we extract the “text” field (if it is empty, use the “resource-id” field), and concatenate them into the natural-language description with the separator (‘;’). \ 3.1.2 Dynamic Hint Extraction. When one inputs an incorrect text into the app, there are some feedbacks (i.e., dynamic hints) related to the inputs, e.g., the app may alter the users that the password should contain letters and digits. The dynamic hint can further help LLM understand what the valid input should look like. \ We extract the dynamic hints via differential analysis which compares the differences of the GUI page before and after inputting the text, and extracts the text field of the newly emerged widgets (e.g., a popup window) in the later GUI page, with examples shown in Figure 2. We also record the text input which makes the dynamic hint happens, which can help the LLM to understand the reason behind it. \ 3.1.3 Candidate Constraints Preparation. Our pilot study in Section 2.1.2 summarizes the categories of constraints within and among the widgets. The information can provide direct guidance for the LLM in generating the valid inputs, for example, the constraint explicitly requires the input should be pure text (without special characters). We provide this list of all candidate constraints described in natural language as in Section 2.1.2 to the LLM. \ 3.1.4 Prompt Generation. With the extracted information, we use three kinds of information to generate prompts for inputting into the LLM, as shown in Table 1. Generally speaking, it first provides the context information and the dynamic hints (if any) of the input widgets, followed by the candidate constraints, and then queries the LLM for the valid input. Due to the robustness of LLM, the generated prompt sentence does not need to fully follow the grammar. \ After inputting the prompt, the LLM will return its recommended valid text input and its inferred constraints, as demonstrated in Figure 4 ②. We then input it into the widget, and check whether it can make the app transfer to the new GUI page (i.e., valid input). If the app fails to transfer, we iterate the process until the valid input is generated. \ \ 3.2 Prompt Generation for Test Generator with Mutation Rule Based on the valid input in the previous section, InputBlaster then leverages LLM to produce the test generator together with the mutation rule. As demonstrated in Figure 4 ⑤, the test generator is a code snippet that can generate a batch of unusual inputs, while the mutation rule is the natural language described operation for mutating the valid inputs which automatically output by LLM based on our prompt and serves as the reasoning chain for producing the test generator. Note that the mutation rule here is output by LLM. \ Each time when a test generator is produced, we can obtain a batch of automatically generated unusual text inputs, and will input them into the text widgets to check whether they have successfully made the mobile app crash. This test execution feedback (in Section 3.2.2) will be incorporated in the prompt for querying the LLM which can enable it more familiar with how the mutation works and potentially produce more diversified outcomes. We also include the inferred constraints in the previous section in the prompt (in Section 3.2.1), since the natural language described explanation would facilitate the LLM in producing effective mutation rules, for example, the inferred constraint is that the input should be in pure text (without special characters) and the LLM would try to insert certain characters to violate the constraint. \ 3.2.1 Inferred Constraints and Valid Input Extraction. We have obtained the inferred constraints and valid input from the output of the LLM in the previous section, here we extract this information from the output message and will input it into the LLM in this section. We design a flexible keyword matching method to automatically extract the description between the terms like ‘constraints’ and ‘the input’ and treat it as the inferred constraints, and extract the description after the terms like ‘input is’ and treat it as the valid input, as demonstrated in Figure 4 ②. \ 3.2.2 Test Execution Feedback Extraction. After generating the unusual text inputs, we input them into the mobile app and check whether they can successfully trigger the app crash. This test execution information will be inputted into the LLM to generate more effective and diversified text inputs. We use the real buggy text inputs and the other unusual inputs (which don’t trigger bugs) to prompt LLM in the follow-up generation. The former can remind the LLM to avoid generating duplicate ones, while the latter aims at telling the LLM to consider other mutation rules. \ Besides, we also associate the mutation rules with the text input to enable the LLM to better capture its semantic meaning. As shown in Figure 4 ⑤, we extract the content between the keywords “Mutation rule” and “Test generator” as mutation rules. \ 3.2.3 Prompt Generation. With the extracted information, we design linguistic patterns of the prompt for generating the test generator and mutation rules. As shown in Figure 4 ④, the prompt includes four kinds of information, namely inferred constraints, valid input, text execution feedback, and question. The first three kinds of information are mainly based on the extracted information as described above, and we also add some background illustrations to let the LLM better understand the task, like the inferred constraint in Figure 4 ④. For the question, we first ask the LLM to generate the mutation rule for the valid input, then let it produce a test generator following the mutation rule. Due to the robustness of LLM, the generated prompt sentence does not need to follow the grammar completely. 3.3 Enriching Prompt with Examples It is usually difficult for LLM to perform well on domain-specific tasks as ours, and a common practice would be employing the in-context learning schema to boost the performance. It provides the LLM with examples to demonstrate what the instruction is, which enables the LLM better understand the task. Following the schema, along with the prompt for the test generator as described in Section 3.2, we additionally provide the LLM with examples of the unusual inputs. To achieve this, we first build a basic example dataset of buggy inputs (which truly trigger the crash) from the issue reports of open-source mobile apps, and continuously enlarge it with the running records during the testing process (in Section 3.3.1). Based on the example dataset, we design a retrieval-based example selection method (in Section 3.3.2) to choose the most suitable examples in terms of an input widget, which further enables the LLM to learn with pertinence. \ \ 3.3.1 Example Dataset Construction. We collect the buggy text inputs from GitHub and continuously build an example dataset that serves as the basis for in-context learning. For each data instance, as demonstrated in 4 ③, it records the buggy text inputs and the mutation rules which facilitate the LLM understanding of how the buggy inputs come from. It also includes the context information of the input widgets which provides the background information of the buggy inputs, and enables us to select the most suitable examples when querying the LLM. \ Mining buggy text inputs from GitHub. First, we automatically crawl the issue reports and pull requests from the Android mobile apps in GitHub (updated before September 2022). Then we use keyword matching to filter these related to the text inputs (e.g., EditText) and have triggered crashes. Following that, we then employ manual checking to further determine whether there is a crash triggered by the buggy text inputs by running the app. In this way, we obtain 50 unusual inputs and store them in the example dataset (There is no overlap with the evaluation datasets.). We then extract the context information of the input widget with the method in Section 3.1.1, and store it together with the unusual input. Note that, since these buggy inputs don’t associate with the mutation rules, we set them as null. \ Enlarging the dataset with buggy text inputs during testing. We enrich the example dataset with the newly emerged unusual text inputs which truly trigger bugs during InputBlaster runs on various apps. Specifically, for each generated unusual text input, after running it in the mobile apps, we put the ones which trigger crashes into the example dataset. We also add their associated mutation rules generated by the LLM, as well as the context information extracted in Section 3.1.1. \ 3.3.2 Retrieval-based Example Selection and In-context Learning. Examples can provide intuitive guidance to the LLM in accomplishing a task, yet excessive examples might mislead the LLM and cause the performance to decline. Therefore, we design a retrieval based example selection method to choose the most suitable examples (i.e., most similar to the input widgets) for LLM. \ In detail, the similarity comparison is based on the context information of the input widgets. We use Word2Vec (Lightweight word embedding method) [50] to encode the context information of each input widget into a 300-dimensional sentence embedding, and calculate the cosine similarity between the input widget and each data instance in the example dataset. We choose the top-K data instance with the highest similarity score, and set K as 5 empirically. \ The selected data instances (i.e., examples) will be provided to the LLM in the format of context information, mutation rule, and buggy text input, as demonstrated in Figure 4 ③. 3.4 Implementation We implement InputBlaster based on the ChatGPT which is released on the OpenAI website[3]. It obtains the view hierarchy file of the current GUI page through UIAutomator [65] to extract context information of the input widgets. InputBlaster can be integrated by replacing the text input generation module of the automated GUI testing tool, which automatically extracts the context information and generates the unusual inputs. \ \ [3] https://beta.openai.com/docs/models/chatgpt
a
a
a
a
a
a
HSBC's new app, Zing, challenges fintech leaders (Revolut and Wise) in FX transfers. Is Zing a game-changer or just another player? Find out!
a
a
a
a
a
a
Non-Fungible Tokens (NFTs) took the digital world by storm in recent years, providing a novel foundation for extreme innovation in digital art, collectibles, and other assets. After an initial frenzy of excitement and exorbitant sales, the NFT market experienced a significant slowdown. Now, signs are pointing to a potential resurgence. But what factors are necessary for NFTs to make a successful comeback?
a
a
a
a
a
a
:::info This paper is available on arxiv under CC 4.0 license. Authors: (1) Zhe Liu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (2) Chunyang Chen, Monash University, Melbourne, Australia; (3) Junjie Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author; (4) Mengzhuo Chen, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (5) Boyu Wu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (6) Zhilin Tian, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (7) Yuekai Huang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (8) Jun Hu, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China; (9) Qing Wang, State Key Laboratory of Intelligent Game, Beijing, China Institute of Software Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China & Corresponding author. ::: Table of Links Abstract and Introduction Motivational Study and Background Approach Experiment Design Results and Analysis Discussion and Threats to Validity Related Work Conclusion and References 2 MOTIVATIONAL STUDY AND BACKGROUND To better understand the constraints of text inputs in real-world mobile apps, we carry out a pilot study to examine their prevalence. We also categorize the constraints, to facilitate understanding and the design of our approach for generating unusual inputs violating the constraints. 2.1 Motivational Study 2.1.1 Data Collection. The dataset is collected from one of the largest Android GUI datasets Rico [19], which has a great number of Android GUI screenshots and their corresponding view hierarchy files [45, 46]. These apps belong to diversified categories such as news, entertainment, medical, etc. We analyze the view hierarchy file according to the package name and extract the GUI page belonging to the same app. A total of 7,136 apps with each having more than 3 GUI pages are extracted. For these apps, we first randomly select 136 apps with 506 GUI pages and check their text inputs through view hierarchy files. We summarize a set of keywords that indicate the apps have text inputs widgets [30], e.g., EditText, hint-text, AutoCompleteTextView, etc. We then use these keywords to automatically filter the view hierarchy files from the remaining 7,000 apps, and obtain 5,761 candidate apps with at least one potential text input widget. Four authors then manually check them to ensure that they have text inputs until a consensus is reached. In this way, we finally obtain 5,013 (70.2%) apps with at least one text input widget, and there are 3,723 (52.2%) apps having two or more text input widgets. Please note that there is no overlap with the evaluation dataset. \ 2.1.2 The Constraint Categories of Text Inputs. We randomly select 2000 apps with text inputs and conduct manual categorization to derive the constraint types of input widgets. Following the open coding protocol [59], two authors individually examine the content of the text input, including the app name, activity name, input type and input content. Then each annotator iteratively merges similar codes, and any disagreement of the categorization will be handed over to the third experienced researcher for double checking. Finally, we come out with a categorization of the constraints within (intra-widget) and among the widgets (inter-widget), with details summarized in Figure 2. \ Intra-widget constraint. Intra-widget constraints depict the requirements of a single text input, e.g., a widget for a human’s height can only input the non-negative number. There are explicit and implicit sub-types. The former accounts for 63%, which manifests as the requirement to display input directly on the GUI page. And the latter account for 37%, mainly manifested as the feedback when incorrect text input is received, e.g., after inputting a simple password, the app would remind the user “at least one upper case character (A-Z) is required” as demonstrated in Figure 2. \ Inter-widget constraint. Inter-widget constraints depict the requirements among multiple text input widgets on a GUI page, for example, the diastolic pressure should be less than systolic pressure as shown in Figure 2. \ Summary. As demonstrated above, the text input widgets are quite common in mobile apps, e.g., 70.2% apps with at least one such widget. Furthermore, considering the diversity of inputs and contexts, it would require significant efforts to manually build a complete set of mutation rules to fully test an input widget, and the automated technique is highly demanded. This confirms the popularity of text inputs in mobile apps and the complexity of it for full testing, which motivates us to automatically generate a batch of unusual text inputs for effective testing and bug detection. 2.2 Background of LLM and In-context Learning The target of this work is to generate the input text, and the Large Language Model (LLM) trained on ultra-large-scale corpus can understand the input prompts (sentences with prepending instructions or a few examples) and generate reasonable text. When pre-trained on billions of samples from the Internet, recent LLMs (like ChatGPT [58], GPT-3 [10] and T5 [56]) encode enough information to support many natural language processing tasks [47, 60, 68]. \ Tuning a large pre-trained model can be expensive and impractical for researchers, especially when limited fine-tuned data is available for certain tasks. In-context Learning (ICL) [11, 25, 51] offers a new alternative that uses Large Language Models to perform downstream tasks without requiring parameter updates. It leverages input-output demonstration in the prompt to help the model learn the semantics of the task. This new paradigm has achieved impressive results in various tasks, including code generation and assertion generation. \
a
a
a
a
a
a
The try block in Rust offers a more elegant solution for error handling, complementing the ? operator by consolidating error checks into a single block. This experimental feature simplifies error management in Rust, reducing boilerplate code and enhancing code readability.
a
a
a
a
a
a
Pre-Seed Stage: Focus is on launching a Minimum Viable Product (MVP), gaining early adopters, generating initial revenue, and collecting feedback. This stage involves refining the product concept, starting market research, and making initial hires. Seed Stage: Aim to confirm product-market fit, build traction, and show potential to investors. Key activities include testing marketing strategies, optimizing customer acquisition costs, and scaling up operations with seed funding. Series A Stage: The goal is scaling up the business and expanding market reach after achieving product-market fit. This includes developing a long-term business model, enhancing the product, and possibly preparing for bigger market capture. Common Challenges: Entry barriers vary by industry, with examples like regulatory hurdles in FinTech. Developing a product involves careful consideration of costs, competition, and regulatory compliance. Best Practices: Early stages should focus on building an MVP and understanding customer needs through interviews. Later stages involve optimizing the tech stack and streamlining operations. Always maintain a clear focus on market needs and regulatory requirements.
a
a
a
a
a
a
Quick Take Bitcoin left a significant mark on the ETF industry in 2024, with Bitcoin ETFs drawing in more than $12 billion in net inflows combined. Leading this surge is BlackRock’s iShares Bitcoin ETF (IBIT), which has accumulated over $15 billion in net inflows and stands at the forefront of this success narrative. Recently, IBIT […] The post IBIT vs GLD: A compelling tale of Bitcoin’s growing dominance over traditional gold investments appeared first on CryptoSlate.
a
a
a
a
a
a
House Financial Services Committee Ranking Member Maxine Waters said a stablecoin bill “in the short run” was coming amid negotiations with Republican lawmakers and the Senate.
a
a
a
a
a
a
ViaBTC sold the fourth ever “epic sat” for over $2.1 million less than a week after mining it during the Bitcoin halving.
a
a
a
a
a
a

Top 100 Coins By Market Cap
NEXT BTC MOVE:
I think Bitcoin goes UP because
| Name | Price | Marketcap | 24h | ||
|---|---|---|---|---|---|
 Bitcoin (BTC)
Bitcoin (BTC)
|
$64,383.63 | $1.26 T | -0.78% | ||
 Ethereum (ETH)
Ethereum (ETH)
|
$3,151.29 | $384.61 B | -0.71% | ||
 Tether USDt (USDT)
Tether USDt (USDT)
|
$0.99954018 | $110.41 B | 0.02% | ||
 BNB (BNB)
BNB (BNB)
|
$612.95 | $90.46 B | 2.35% | ||
 Solana (SOL)
Solana (SOL)
|
$147.53 | $65.95 B | -2.89% | ||
 USDC (USDC)
USDC (USDC)
|
$1.00 | $33.24 B | 0.02% | ||
 XRP (XRP)
XRP (XRP)
|
$0.52643105 | $29.02 B | -0.58% | ||
 Dogecoin (DOGE)
Dogecoin (DOGE)
|
$0.15150421 | $21.82 B | -0.98% | ||
 Toncoin (TON)
Toncoin (TON)
|
$5.43 | $18.85 B | -1.76% | ||
 Cardano (ADA)
Cardano (ADA)
|
$0.47216511 | $16.83 B | -0.79% | ||
 Shiba Inu (SHIB)
Shiba Inu (SHIB)
|
$0.00002581 | $15.21 B | -0.45% | ||
 Avalanche (AVAX)
Avalanche (AVAX)
|
$35.62 | $13.42 B | -3.91% | ||
 TRON (TRX)
TRON (TRX)
|
$0.11667000 | $10.21 B | 2.88% | ||
 Polkadot (DOT)
Polkadot (DOT)
|
$6.92 | $9.92 B | -1.85% | ||
 Bitcoin Cash (BCH)
Bitcoin Cash (BCH)
|
$478.90 | $9.41 B | -0.54% | ||
 Chainlink (LINK)
Chainlink (LINK)
|
$14.72 | $8.63 B | -0.70% | ||
 NEAR Protocol (NEAR)
NEAR Protocol (NEAR)
|
$7.12 | $7.57 B | 0.71% | ||
 Polygon (MATIC)
Polygon (MATIC)
|
$0.71580000 | $7.06 B | -0.29% | ||
 Internet Computer (ICP)
Internet Computer (ICP)
|
$13.73 | $6.34 B | -1.05% | ||
 Litecoin (LTC)
Litecoin (LTC)
|
$83.98 | $6.24 B | -0.71% | ||
 UNUS SED LEO (LEO)
UNUS SED LEO (LEO)
|
$5.80 | $5.37 B | 0.58% | ||
 Dai (DAI)
Dai (DAI)
|
$1.00 | $5.35 B | 0.03% | ||
 Uniswap (UNI)
Uniswap (UNI)
|
$8.06 | $4.81 B | 3.82% | ||
 First Digital USD (FDUSD)
First Digital USD (FDUSD)
|
$1.00 | $4.42 B | 0.07% | ||
 Hedera (HBAR)
Hedera (HBAR)
|
$0.11856880 | $4.24 B | -1.06% | ||
 Stacks (STX)
Stacks (STX)
|
$2.70 | $3.92 B | -0.97% | ||
 Aptos (APT)
Aptos (APT)
|
$9.11 | $3.88 B | -2.22% | ||
 Ethereum Classic (ETC)
Ethereum Classic (ETC)
|
$26.40 | $3.86 B | -2.05% | ||
 Mantle (MNT)
Mantle (MNT)
|
$1.14 | $3.71 B | 2.02% | ||
 Cronos (CRO)
Cronos (CRO)
|
$0.12634032 | $3.36 B | 0.73% | ||
 Pepe (PEPE)
Pepe (PEPE)
|
$0.00000794 | $3.34 B | 7.82% | ||
 Stellar (XLM)
Stellar (XLM)
|
$0.11420000 | $3.30 B | -1.61% | ||
 Render (RNDR)
Render (RNDR)
|
$8.51 | $3.27 B | -1.25% | ||
 Cosmos (ATOM)
Cosmos (ATOM)
|
$8.37 | $3.27 B | -1.55% | ||
 Filecoin (FIL)
Filecoin (FIL)
|
$6.03 | $3.26 B | -1.72% | ||
 dogwifhat (WIF)
dogwifhat (WIF)
|
$3.21 | $3.18 B | -0.63% | ||
 Hedera Hashgraph (HBAR)
Hedera Hashgraph (HBAR)
|
$0.11890000 | $4.22 B | -1.56% | ||
 OKB (OKB)
OKB (OKB)
|
$53.04 | $3.18 B | -2.85% | ||
 Bittensor (TAO)
Bittensor (TAO)
|
$462.61 | $3.08 B | 1.25% | ||
 Immutable (IMX)
Immutable (IMX)
|
$2.11 | $3.06 B | -6.89% | ||
 Arbitrum (ARB)
Arbitrum (ARB)
|
$1.10 | $2.91 B | -2.83% | ||
 VeChain (VET)
VeChain (VET)
|
$0.04012000 | $2.91 B | -0.96% | ||
 Kaspa (KAS)
Kaspa (KAS)
|
$0.11992510 | $2.81 B | -4.25% | ||
 Maker (MKR)
Maker (MKR)
|
$2,857.00 | $2.64 B | -0.37% | ||
 The Graph (GRT)
The Graph (GRT)
|
$0.26799620 | $2.54 B | -2.41% | ||
 Optimism (OP)
Optimism (OP)
|
$2.43 | $2.54 B | -0.50% | ||
 Injective (INJ)
Injective (INJ)
|
$26.54 | $2.48 B | -2.08% | ||
 Theta Network (THETA)
Theta Network (THETA)
|
$2.46 | $2.44 B | 4.28% | ||
 Monero (XMR)
Monero (XMR)
|
$119.72 | $2.21 B | -0.43% | ||
 Fantom (FTM)
Fantom (FTM)
|
$0.75553089 | $2.12 B | 2.49% | ||
 Core (CORE)
Core (CORE)
|
$2.35 | $2.07 B | -5.14% | ||
 Arweave (AR)
Arweave (AR)
|
$31.64 | $2.05 B | -4.03% | ||
 Fetch.ai (FET)
Fetch.ai (FET)
|
$2.32 | $1.96 B | -4.62% | ||
 Celestia (TIA)
Celestia (TIA)
|
$10.87 | $1.96 B | -2.36% | ||
 Bonk (BONK)
Bonk (BONK)
|
$0.00002901 | $1.89 B | 14.22% | ||
 FLOKI (FLOKI)
FLOKI (FLOKI)
|
$0.00019363 | $1.85 B | 4.22% | ||
 THORChain (RUNE)
THORChain (RUNE)
|
$5.51 | $1.85 B | -0.61% | ||
 Lido DAO (LDO)
Lido DAO (LDO)
|
$2.04 | $1.81 B | -0.74% | ||
 Sei (SEI)
Sei (SEI)
|
$0.63020000 | $1.76 B | 6.16% | ||
 Bitget Token (BGB)
Bitget Token (BGB)
|
$1.19 | $1.66 B | -3.13% | ||
 Algorand (ALGO)
Algorand (ALGO)
|
$0.20360000 | $1.65 B | -4.39% | ||
 Render Token (RNDR)
Render Token (RNDR)
|
$8.56 | $3.27 B | -1.39% | ||
 Sui (SUI)
Sui (SUI)
|
$1.23 | $1.59 B | -3.33% | ||
 Beam (BEAM)
Beam (BEAM)
|
$0.02828245 | $1.50 B | 2.02% | ||
 Gala (GALA)
Gala (GALA)
|
$0.04840000 | $1.46 B | 0.20% | ||
 Pendle (PENDLE)
Pendle (PENDLE)
|
$6.02 | $1.44 B | -2.75% | ||
 Jupiter (JUP)
Jupiter (JUP)
|
$1.05 | $1.42 B | -4.29% | ||
 Flow (FLOW)
Flow (FLOW)
|
$0.92700000 | $1.39 B | -3.22% | ||
 Aave (AAVE)
Aave (AAVE)
|
$90.95 | $1.34 B | -1.87% | ||
 Bitcoin SV (BSV)
Bitcoin SV (BSV)
|
$66.96 | $1.32 B | -3.06% | ||
 Quant (QNT)
Quant (QNT)
|
$109.50 | $1.32 B | 1.00% | ||
 Ethena (ENA)
Ethena (ENA)
|
$0.88800000 | $1.25 B | -1.85% | ||
 Neo (NEO)
Neo (NEO)
|
$17.77 | $1.25 B | -1.68% | ||
 BitTorrent (New) (BTT)
BitTorrent (New) (BTT)
|
$0.00000127 | $1.23 B | -0.62% | ||
 SingularityNET (AGIX)
SingularityNET (AGIX)
|
$0.95546000 | $1.22 B | -3.87% | ||
 Flare (FLR)
Flare (FLR)
|
$0.03050632 | $1.18 B | -2.20% | ||
 Wormhole (W)
Wormhole (W)
|
$0.64671606 | $1.16 B | 16.90% | ||
 MultiversX (EGLD)
MultiversX (EGLD)
|
$42.35 | $1.13 B | -0.51% | ||
 Huobi Token (HT)
Huobi Token (HT)
|
$0.58389800 | $93.19 M | 1.98% | ||
 Akash Network (AKT)
Akash Network (AKT)
|
$4.76 | $1.12 B | -2.94% | ||
 Axie Infinity (AXS)
Axie Infinity (AXS)
|
$7.44 | $1.06 B | -3.47% | ||
 Chiliz (CHZ)
Chiliz (CHZ)
|
$0.11950000 | $1.06 B | -1.48% | ||
 dYdX (Native) (DYDX)
dYdX (Native) (DYDX)
|
$2.27 | $1.06 B | -0.45% | ||
 The Sandbox (SAND)
The Sandbox (SAND)
|
$0.46510000 | $1.05 B | -1.71% | ||
 eCash (XEC)
eCash (XEC)
|
$0.00005197 | $1.02 B | -0.90% | ||
 Conflux (CFX)
Conflux (CFX)
|
$0.25630000 | $1.01 B | 3.46% | ||
 dYdX (DYDX)
dYdX (DYDX)
|
$2.26 | $706.90 M | -0.92% | ||
 Tezos (XTZ)
Tezos (XTZ)
|
$1.02 | $996.79 M | 0.11% | ||
 Ronin (RON)
Ronin (RON)
|
$3.10 | $979.70 M | -5.29% | ||
 EOS (EOS)
EOS (EOS)
|
$0.85970000 | $964.56 M | 2.96% | ||
 KuCoin Token (KCS)
KuCoin Token (KCS)
|
$9.99 | $960.48 M | 0.72% | ||
 Synthetix (SNX)
Synthetix (SNX)
|
$2.91 | $955.23 M | 0.34% | ||
 Worldcoin (WLD)
Worldcoin (WLD)
|
$4.91 | $954.51 M | -4.14% | ||
 Mina (MINA)
Mina (MINA)
|
$0.85818309 | $937.50 M | -2.31% | ||
 JasmyCoin (JASMY)
JasmyCoin (JASMY)
|
$0.01895100 | $930.83 M | -2.03% | ||
 Pyth Network (PYTH)
Pyth Network (PYTH)
|
$0.61770000 | $923.71 M | -1.97% | ||
 ORDI (ORDI)
ORDI (ORDI)
|
$43.55 | $914.47 M | -2.29% | ||
 Decentraland (MANA)
Decentraland (MANA)
|
$0.46727920 | $891.72 M | -0.80% | ||
 Starknet (STRK)
Starknet (STRK)
|
$1.19 | $867.40 M | -4.50% | ||
 Gnosis (GNO)
Gnosis (GNO)
|
$332.10 | $860.68 M | -4.52% |
Try to search another coin





clc7 Bitcoin